Ubuntu ZFS Cheat Sheet
General guidelines to setup and tune ZFS with Ubuntu

I graduated from a Raspberry Pi for my home server and have been exploring how to configure ZFS on Ubuntu for some time. This article is a summary of the information I wish was compiled when I first learned about ZFS and got it running on Ubuntu for the first time.
I've created the cheat sheet below as general guidelines when creating your ZFS layout for Ubuntu.
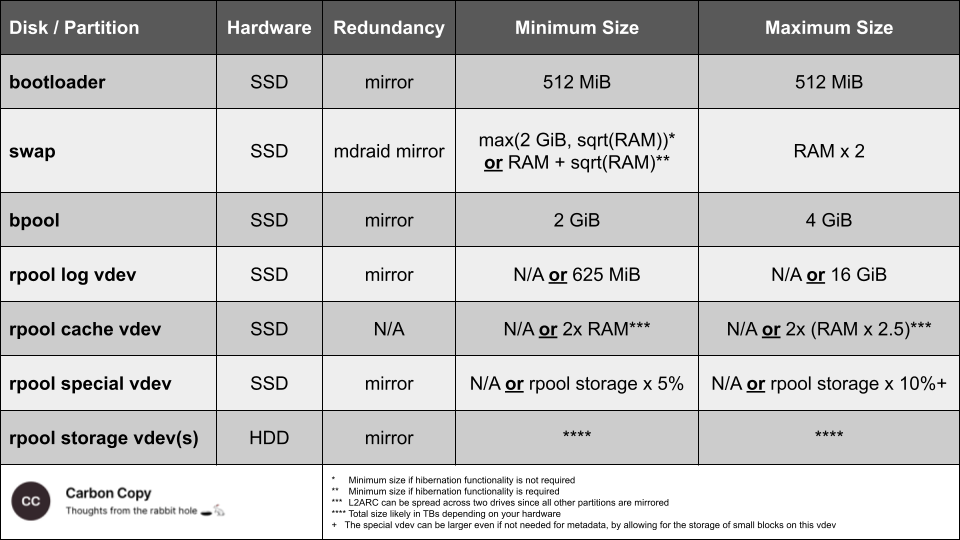
These work well for me, but your mileage may vary, and your hardware and usage patterns may merit a different setup. I'm not a professional system administrator, so if you find errors, tweaks, or more nuanced guidelines that work better in different situations, please share them with me so I can reference and update this article and cheat sheet accordingly.
If you are unfamiliar with ZFS, you can read more about it here and here.
See this guide for a complete set of instructions to install Ubuntu with root on ZFS.
Disks and Partitions
Below, I provide layman's heuristics and considerations to determine a ZFS layout for Ubuntu based on your hardware and use cases.
- Bootloader: This is where your bootloader will reside to select our OS upon boot or enter recovery mode. 512 MiB is sufficient.
- Swap partition: The swap partition is where your server parks data when fully utilizing your RAM. The swap partition should not be less than the greater of 2GiB or the square root of your RAM. Your swap partition doesn't provide any performance benefits after reaching double your RAM size. If for whatever reason, your server will hibernate, the minimum size of your swap partition should be your RAM plus the square root of your RAM. The only downside to a larger swap partition is that you would be unable to use that data for something else, whereas too small a swap partition may lead to performance loss or crashes. If disk space is not an issue given the other considerations, you can shortcut this decision and allocate double the size of your RAM. Some advocate that you don't need a swap partition with ZFS, and others still prefer it, primarily for debugging after crashes, but also if you use 'tmpfs' for /tmp, which we will, to prevent out-of-memory situations.
- Boot pool partition: This is 'bpool' in Ubuntu, which requires a minimum of 500MiB and a maximum of 2GiB. If disk space is not an issue, you can allocate 4GiB to be safe, as there are varying reports here and here regarding the minimum requirements.
- Root pool partition(s): If you glanced at the Ars Technica primer, you would have noticed that zpools are the highest level of the ZFS storage hierarchy, comprised of one or more vdevs. These vdevs must include at least one storage vdev and up to three support vdevs.
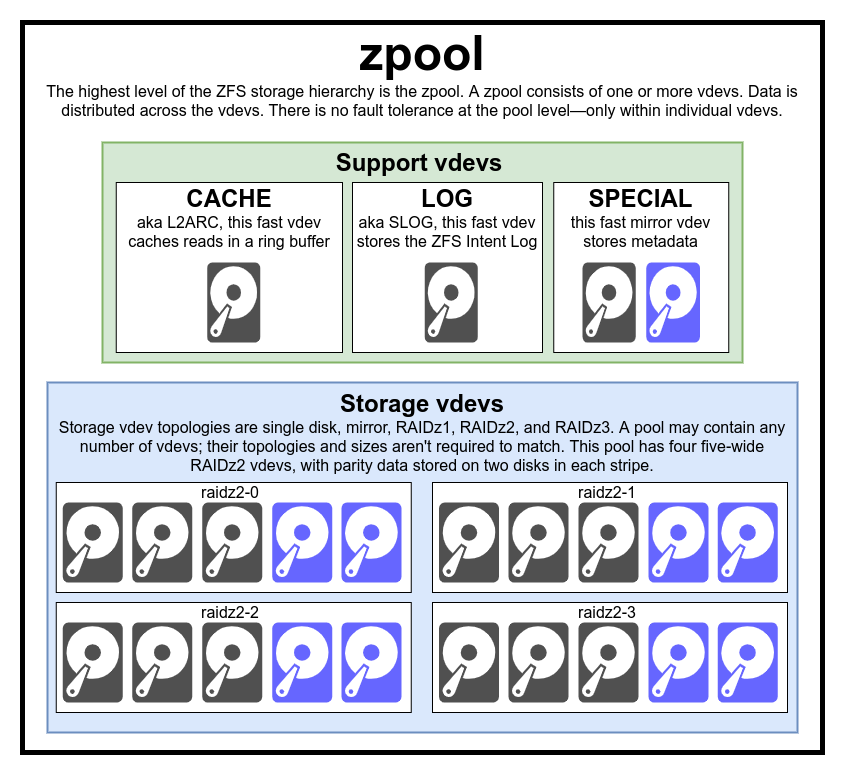
Below are two videos covering the support vdevs and how and when to use them. The first video by Lawrence Systems is an excellent overview of cache and log vdevs.
The second video is by Level1Linux and provides an overview of the special device vdev.
Below are some rules of thumb to determine your need for these support vdevs and how much space to allocate to each partition.
- Cache (i.e., L2ARC): ZFS uses a portion of your RAM as an ARC (Adaptive Read Cache). An L2ARC is a read cache that resides on an SSD (solid state drive). Somewhat counterintuitively, however, an L2ARC requires additional space in RAM and may reduce overall performance for most builds instead of helping it. In general, if a system has less than 64GB of RAM, L2ARC is likely detrimental to performance. For systems with more RAM, the size of the L2ARC should not exceed five times the amount of RAM. Your cache vdev need not be mirrored or redundant in any other way. Since the L2ARC contains exact copies of data in your storage vdevs, you can fully recover a zpool even if the cache vdev fails.
- Log (i.e., ZIL): The ZIL (ZFS Intent Log) is a storage area that temporarily holds a synchronous write cache until ZFS writes this data to the storage vdevs in the zpool. Whether or not you allocate a separate disk or partition to it, ZFS always uses a ZIL. Including the ZIL as a SLOG (separate log) on an SSD should improve performance if you are operating synchronous writes, such as busy Network File Systems (NFS) or databases. If you don't allocate a SLOG, your ZIL resides on your spinning hard disks, and the performance of those disks binds its performance. If you use a dedicated SLOG, the maximum amount of space you will need is 16 GB (though likely a lot less). Of further note, IXSystems claims that adding other caching functions on the same SSD as the SLOG may hurt performance, though this may not be as detrimental as claimed given its widespread use in online communities, as seen here, here, and here. You can read more about ZIL/SLOG from Jim Salter here. You should mirror your log vdev to avoid catastrophic situations as described here and here.
- Special (aka., special allocation): The special allocation class was introduced with ZFS version 0.8 and primarily serves to index metadata that resides in storage vdevs. This indexing can significantly improve random I/O operations on slower disks when allocated to an SSD. In addition, the special vdev can directly store file blocks below a specific size as a secondary function. However, there are potential issues, such as ensuring that the number of small files does not become so significant to push the metadata out of the special vdev to the slower storage vdev. You can avoid these issues by setting a small enough file size and adding a quota to the file storage above and beyond metadata. You can read more about this vdev here and here. You should target your special vdev to be 5-10% of the size of your storage vdev(s). If you have extra space, you can use the special vdev to store small files. If you have less than the ideal amount of space, you can consider eliminating your L2ARC or accepting the metadata flowing back into the slower disks. Lastly, you should always mirror the special vdev as the entire zpool will be irrecoverable if the special vdev becomes unavailable.
- Storage: A sole storage vdev is the only mandatory vdev required to create a zpool. As noted in the diagram above, there is no redundancy at the zpool level, and you need to implement redundancies at the vdev level. The generally applicable best practice is a well-tuned pool of mirrors, where tuning includes appropriately sized cache, log, and special vdevs and creating different datasets within the zpool with appropriate record sizes for the data type in a specific dataset. Mirroring refers to having at least one complete copy of every disk (stand-alone drive or partition). While more than two mirrored devices within a vdev are possible, it's likely overkill. But your storage vdevs must be in pairs to have a better chance of avoiding data loss as the entire zpool will become inaccessible if any vdev within it fails. For example, if you have two spinning hard disks, you will create one storage vdev. With four, you would create two mirrored vdevs, and so on.
Datasets and Record Sizes
You can have multiple datasets within a zpool, and more importantly, you can assign each dataset a specific record size. ZFS stores data in records, and the default record size at zpool creation is 128 KiB. This record size is the maximum size for a given record, and records may still be smaller. In general, you can improve your server's performance by setting a dataset's record size in line with that dataset's typical workload.
If you want to keep it simple, an untuned default of 128 KiB for all datasets may work fine. Still, you can gain additional performance by adjusting the record size of media folders to 1 MiB and datasets containing SQL databases to 16 KiB. You can read more about the trade-offs associated with ZFS record sizes here. Some real-world tests indicate that 16 KiB record sizes for SQL databases noticeably improve performance.
Additionally, you can consider setting 'special_small_blocks' for certain datasets to store small blocks in the special vdev. For example, if your record size is 1 MiB, ZFS will split any file larger than 1 MiB into pieces, with the last bit likely smaller than 1 MiB. You want to use this setting to allow low-latency access to files smaller than some size, but you will inevitably end up storing some of the smaller tail blocks of larger files in your special vdev as well.
Snapshots and Replication
Snapshots and their easy replication to onsite or offsite "backups" is one of the most powerful features of ZFS. To automate your snapshots and replications, you will want to get cron jobs set up for sanoid and syncoid, where sanoid automates the snapshots your system takes, and the syncoid automates the replication of your datasets to other drives. See more about the installation and configuration of these tools here.
Final Words
You will inevitably run into issues you need to troubleshoot as you toy around with Ubuntu and ZFS. I recommend searching the archives of r/zfs or posting detailed descriptions of your problems on the subreddit if you get stuck. The community may not seem that active, but I've been able to find solutions to nearly all of my problems in their archives. Good luck!